Deduplication algorithm
Finding is a result of single scan, which contains some information about a vulnerability. Parent finding is the first finding for a vulnerability, it creates an issue.
Issue is an entity in Vampy, which contains all information about a vulnerability, received from the finding.
Finding is considered as duplicate, if during import and work of deduplication algorithm an existing matching issue was found. In this case duplicate finding is linked to the issue.
If the duplicate is defined, it links to the issue and is shown in Duplicate section. The data in the issue is taken from parent finding, duplicate findings do not update it. The only field that may be updated is solution.
Deduplication is an algorithm which helps Vampy to recognize identical issues in scan results.
Scan result contains several findings, which include several fields, depending on the scanner. Usually all scans contain repository name, branch name, and an internal scanner duplicate fingerprint - SD ID, but some fields are specific for differend kinds of scanners.
| SAST | SCA | DAST |
|---|---|---|
| CVE | CVE | CVE |
| CWE | CWE | CWE |
| file path | file path | IP |
| file line number | file line number | domain name |
| code snippet | library name | |
| library version |
The main problem is that not all scanners fill those fields, so sometimes we might get several findings from different scanners, which basically refer to the same issue. For every finding Vampy creates a few hashes from the fields the finding has. They are used to compare findings to existing issues to find out if we received a duplicate or we have to create a new issue.
So, we create following hashes for each finding.
| Priority of hash, when comparing | SAST | SCA | DAST |
|---|---|---|---|
| 1 | repository + branch + SD ID (required SD ID) |
repository + branch + SD ID (required SD ID) |
repository + branch + SD ID (required SD ID) |
| 2 | repository + branch + CVE + CWE + filepath + code snippet (required filepath and code snippet) |
repository + branch + CVE + CWE + filepath + file line number + library name + library version (required library name and library version) |
repository + branch + CVE + CWE + domain name + IP address (required CVE) |
| 3 | repository + branch + CVE + CWE + filepath + file line number (required filepath and file line number) |
repository + branch + CVE + CWE + filepath + file line number + library name (required library name and empty (for search) library version) |
repository + branch + CVE + CWE + title |
| 4 | repository + branch + CVE + CWE + filepath + file line number + code_snippet + title | repository + branch + CVE + CWE + filepath + file line number + library name + library version + title |
Once new findings are linked to existing issue, so are their hashes. In the end we have an issue, which has multiple hashes, obtained from all findings linked to it.
Examples
SAST
So, let's say we have 2 findings, A as parent and B as a finding to be checked for being a duplicate. They have all fields for SAST, A was found by Semgrep and B by Checkmarx. What does it look like in our system? Red arrows show the path for our examples.
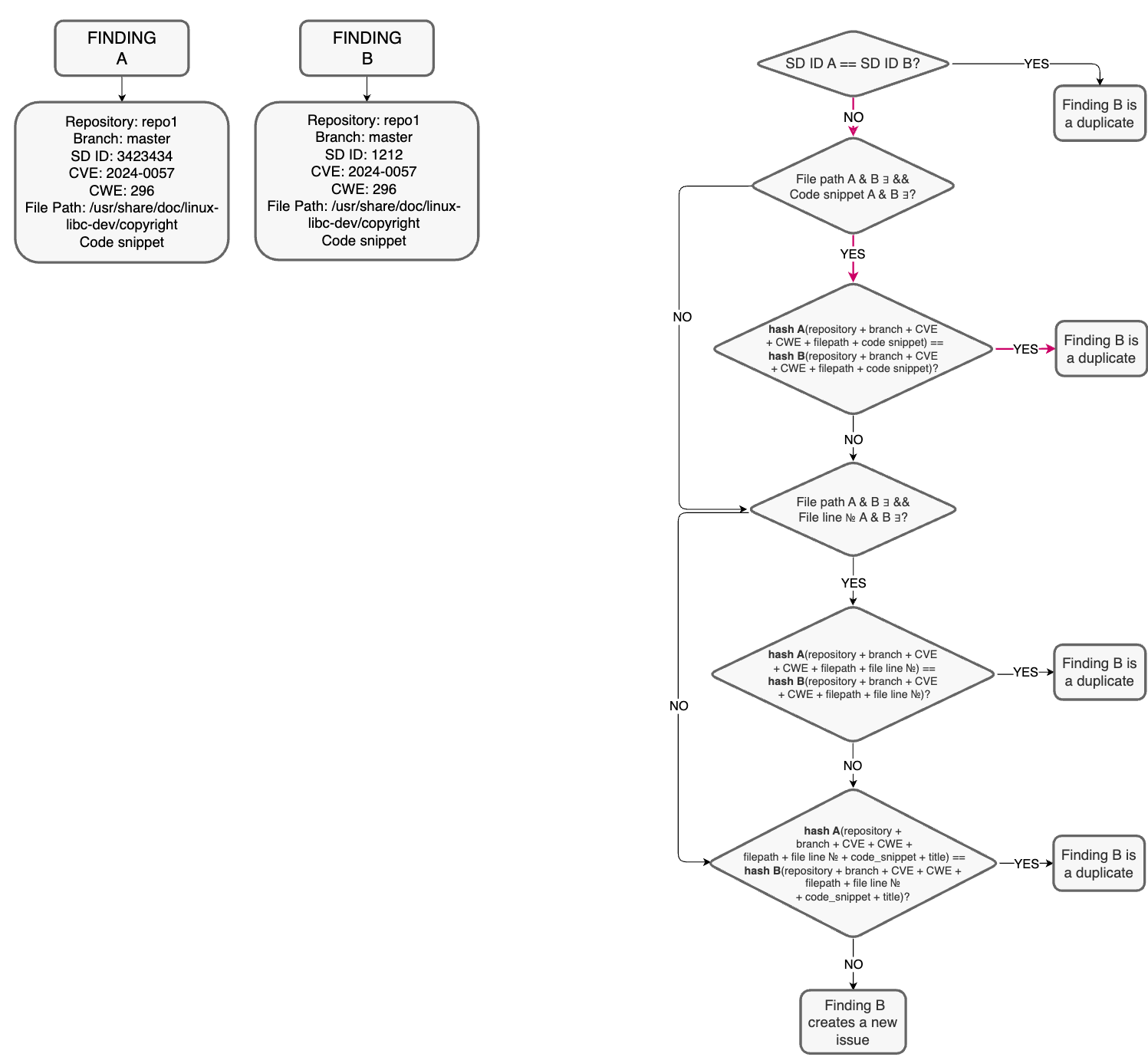
Here we can see that they do not match, since they got different fingerprints, which came from different scanners. But when we check other fields, we understand that it's the same issue.
SCA
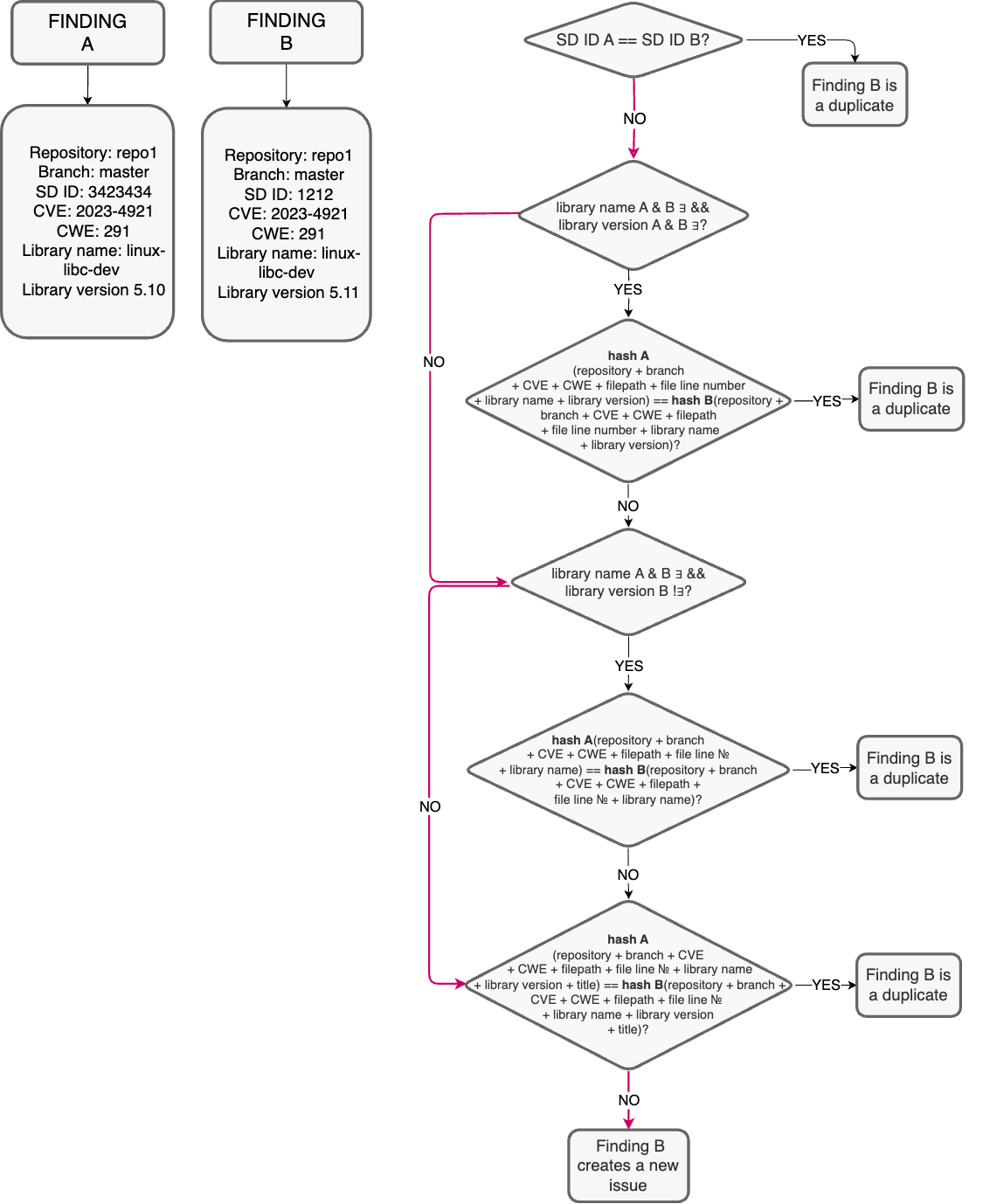
We found Finding A, with all fields filled. It describes a vulnerability with a piece of code, supported by some library v1.0. We upgraded version of library to v1.1, but the vulnerability didn't go anywhere and the next scan brings us Finding B.
The scheme looks pretty simple here.
Issue statuses
Basically there are 4 statuses for issues:
- New Issue,
- Recurrent,
- Fixed,
- Reopened.
When we upload new scan and the algorithm finds duplicates, it turns New Issue into Recurrent and Fixed into Reopened.
When the algorithm found no duplicates for existing issues, it sets all of them to Fixed.